
이번 글에서는 최근 주목받고 있는 Document AI 분야에 대해서 알아보고 OCR 기술의 주요 연구 트렌드에 대해서 살펴보고 향후 OCR 기술의 발전 방향에 대해서 예상해 보도록 하겠습니다.
OCR 분야의 최신 연구 흐름
기존의 OCR 기술은 문서 내의 글자만을 판독하는 목적으로 주로 사용이 되었습니다. 아래의 그림과 같이 주로 Text Detection과 Text Recognition의 두 단계로 구성되는 것이 일반적입니다. 최근에는 이 두 단계를 End-to-End 구조로 통일하는 연구들이 소개되는 추세입니다.

AI 분야의 연구가 발전함에 따라서 이미지 혹은 문서 내에서 글자만을 추출하는 것이 목적이었던 기존의 OCR을 넘어서서 문서의 내용을 이해하여 좀 더 고차원적인 기능을 수행하는 분야를 Document AI라는 용어로 부르기도 합니다.
Document AI 관련 최근 연구 트렌드를 살펴보려면 OCR 분야에서 가장 권위 있는 챌린지인 ICDAR (International Conference on Document Analysis and Recognition)이 주관하는 Robust Reading Competition의 내용들을 알아볼 필요가 있습니다. 해당 챌린지는 격년으로 열리는데 이번에 진행된 챌린지 트랙들을 살펴보면 이전 OCR 챌린지 트랙들과 달리 문서 내의 정보를 추출하는 Information Extraction task와 질의에 대한 답을 수행하는 Question Answering task, Video 내에서의 Text Tracking task가 주를 이루고 있습니다.

각 트랙이 어떤 task로 구성되어 있는지 그림을 통해 간단히 살펴보겠습니다.
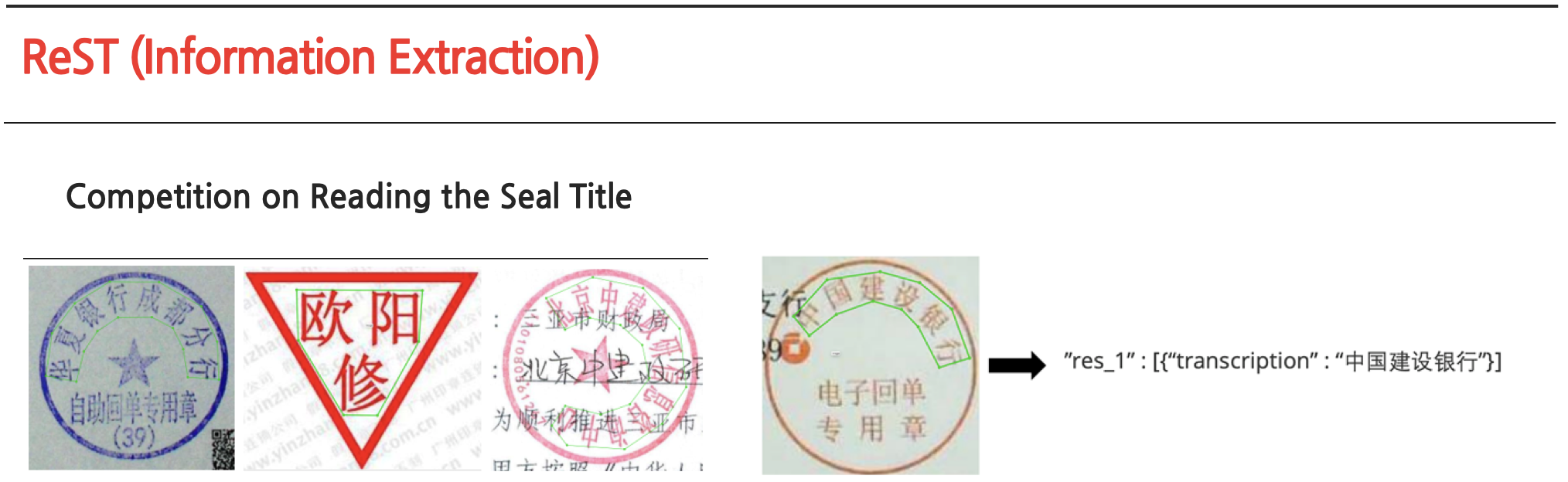






각 트랙의 task를 살펴보면 이미지 내의 정보에 대한 이해를 바탕으로 기존 OCR의 기능에 비해 고차원적인 정보 추출 및 Q/A를 수행하는 것을 알 수 있습니다.
Document AI를 위한 pre-trained model - LayoutLM
위에서 소개된 트랙들의 1위 알고리즘들을 살펴보면 LayoutLM이라는 Document AI를 위한 pre-trained model을 활용하여 알고리즘의 성능을 확보한 경우들을 확인할 수 있습니다. LayoutLM은 Microsoft Research Asia가 참여한 연구로 현재 LayoutLM v3까지 후속 연구가 이어져 활발히 사용되고 있는 모델입니다. NLP 분야의 BERT 모델의 구조 및 학습 방법론을 문서 영역으로 확장하여 적용한 연구로서 Document AI를 위한 범용적인 pre-trained model을 목적으로 하며, 세부 downstream task를 위해 fine-tuning을 수행하는 방식으로 모델을 활용할 수 있습니다.

저자는 pre-trained 모델을 활용하여 Form Understanding, Receipt Understanding, Document Image Classification task를 성공적으로 수행할 수 있음을 보이면서 해당 모델이 Document AI의 표준적인 모델로 자리잡을 수 있음을 보여주었습니다.
OCR과 Large Language Model의 만남
chatGPT의 엄청난 흥행 이후로 기존의 OCR 모델과 LLM을 결합하여 좀 더 복잡한 문서 이해를 수행하는 연구가 소개되고 있습니다. 기존의 OCR 기술을 통해 문서 내의 글자 위치 및 텍스트 정보를 추출한 후 이것을 LLM 모델의 입력으로 사용하는 형태가 일반적입니다.

올해 초에 소개된 업스테이지의 아숙업 (Ask Up) 서비스에서도 OCR 기술을 활용한 챗봇 서비스를 선보인 바 있는데 홍보 내용에 따르면 자사의 OCR 기술과 LLM 기술이 결합된 형태로 구성이 되어 있음을 알 수 있습니다. 이렇게 LLM 모델이 결합된 경우는 문서 내의 글자 판독뿐만이 아니라 주요 정보에 요약 등 좀 더 고차원적인 기능을 수행할 수 있다는 장점이 있어서 향후 기술이 발전함에 따라 그 활용도가 매우 높아질 것으로 예상됩니다.
OCR-free End-to-End 모델
또 하나의 주요한 연구 흐름으로는 기존의 Detection과 Recognition의 OCR 단계를 사용하지 않고 트랜스포머 기반의 단일 네트워크 구조로 다양한 OCR task를 수행하려는 End-to-End 모델 연구가 있습니다.

Dessurt 모델은 이러한 단일 구조의 설계를 기반으로 9가지 종류의 downstream task를 fine-tune을 통해 수행할 수 있음을 보여주었습니다. 비슷한 시기에 CLOVA와 Upstage에서 선보인 Donut 모델 또한 유사한 계열의 연구로 볼 수 있습니다. 점차 트랜스포머 기반의 모델 연구들이 다양한 task에 대해서 좋은 성능을 보여주고 있기 때문에 이러한 End-to-End 접근이 기존 OCR 연구의 성능을 따라잡고 기존 연구를 대체할 가능성이 충분해 보입니다. 다만 모델의 크기가 크고 다량의 데이터를 학습하기 위해 요구되는 GPU 자원이 방대하다는 점은 실용적인 측면에서 단점이 존재합니다.
마치며...
이상으로 최근 주목받고 있는 연구 트렌드인 Document AI의 발전 방향에 대해서 간략히 살펴보았습니다. 특정 문서 양식에 대해 매우 높은 글자 인식 정확도를 요하는 비즈니스 영역에서는 여전히 Detection과 Recognition의 단계를 활용한 기존 방식의 OCR 연구에 대한 수요가 있을 것으로 예상됩니다. 그러나 chatGPT의 흥행 이후로 좀 더 사용자 친화적인 유연한 질의응답 기반의 기능에 대한 요구가 생기면서 장기적으로 LLM을 결합한 방식 혹은 OCR-free 기반의 End-to-End 모델의 연구가 계속될 것으로 예상되며 머지않은 미래에 해당 모델들이 기존의 전통적인 방식의 OCR 모델을 대체하게 될 것으로 조심스럽게 예상합니다. 재미있게 읽어주셨다면 감사드립니다.
참고문헌
[1] Yiheng Xu et al: LayoutLM: Pre-training of Text and Layout for Document Image Understanding. In KDD, 2020.
[2] Jacob Devlin et al: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In arXiv,2019.
[3] Geewook Kim et al: OCR-free Document Understanding Transformer. In ECCV, 2022.
[4] Brian Davis et al: End-to-end Document Recognition and Understanding with Dessurt. In arXiv, 2022.