
최근 멀티모달 분야의 연구가 활발해지면서 다양한 Text-to-Image Generation 모델이 등장하고 있습니다. 그 중 대표적인 GPT 기반 모델에는 DALL-E[1], Make-A-Scene[2], Parti 등이 있습니다. 최근에는 GLIDE, Imagen, LDM 등과 같은 Diffusion 모델들이 주목을 받고 있습니다.
그 중 살펴보고자 하는 모델은 2022년 3월 Meta AI에서 발표한 Make-A-Scene 입니다. OpenAI의 DALL-E 모델에서 세그멘테이션 예측이 추가된 모델으로, GPT 모델은 세그멘테이션 토큰(Segmentation tokens)을 예측한 이후 이미지 토큰(Image tokens)을 예측합니다. 또 Make-A-Scene 모델에 세그멘테이션 토큰을 입력으로 제공하고, 이미지 토큰을 예측할 수도 있습니다.

저희는 이번 게시글에서 Make-A-Scene보다 작은 크기의 모델과 데이터셋을 사용한 mini Make-A-Scene을 학습한 과정을 공유하려고 합니다. mini Make-A-Scene에서 사용한 데이터셋과 각 모듈에 대해 설명드리겠습니다.
데이터셋
mini Make-A-Scene은 아래와 같이 Make-A-Scene 보다 작은 14M의 이미지-텍스트 페어 데이터셋을 사용했습니다.
| 모델 | 모듈 | 데이터셋 | 데이터셋 크기 |
|---|---|---|---|
| Make-A-Scene | VQ-SEG | MS-COCO, CC3M, CC12M | 14M |
| VQ-IMG | MS-COCO, CC3M, CC12M | 14M | |
| GPT | CC3M, CC12M, YFCC100M, Redcaps | 35M | |
| mini Make-A-Scene | VQ-SEG | MS-COCO, CC3M, CC12M | 14M |
| GPT | CC3M, CC12M | 14M |
텍스트 인코더
텍스트 인코더는 DALL-E, Make-A-Scene 모델과 마찬가지로 Byte Pair Encoding을 사용합니다. Byte Pair Encoding은 빈도 수가 가장 많은 페어를 하나의 캐릭터로 압축하여 단어 사전을 구축하고, 이를 기반으로 토크나이징을 하는 방법입니다. 이 때 하이퍼파라미터인 단어 사전 크기의 경우 DALL-E와 동일한 16,384를 사용하였고, GPT와 동일한 데이터셋을 사용하여 학습했습니다.
| 데이터셋 | 데이터셋 크기 | 단어사전 크기 (Vocabulary size) |
|---|---|---|
| CC3M, CC12M | 14M | 16,384 |
GPT 기반 모델 중 비교적 최신 모델인 Parti의 경우 트랜스포머 인코더를 사용하였고, Diffusion 기반 모델인 Imagen은 CLIP의 텍스트 인코더나 T5와 같은 모델을 텍스트 인코더로 사용하여 성능을 끌어올렸습니다. 이를 미루어 보았을 때 Make-A-Scene 모델에서도 텍스트 인코더를 다른 것으로 교체한다면 성능을 올릴 수 있을 것이라 생각됩니다.
세그멘테이션 토크나이저
세그멘테이션 토크나이저의 모델은 VQ-VAE[3]를 사용합니다. VQ-VAE는 인코더, 디코더를 통해 세그멘테이션을 복원할 수 있도록 학습되며, 인코더를 통해 얻을 수 있는 Latent Space Representation인 세그멘테이션 토큰을 GPT 모델 학습에 사용합니다. 또한 디코더를 통해 GPT 모델이 예측한 세그멘테이션 토큰을 디코딩하여 세그멘테이션을 확인할 수 있습니다.
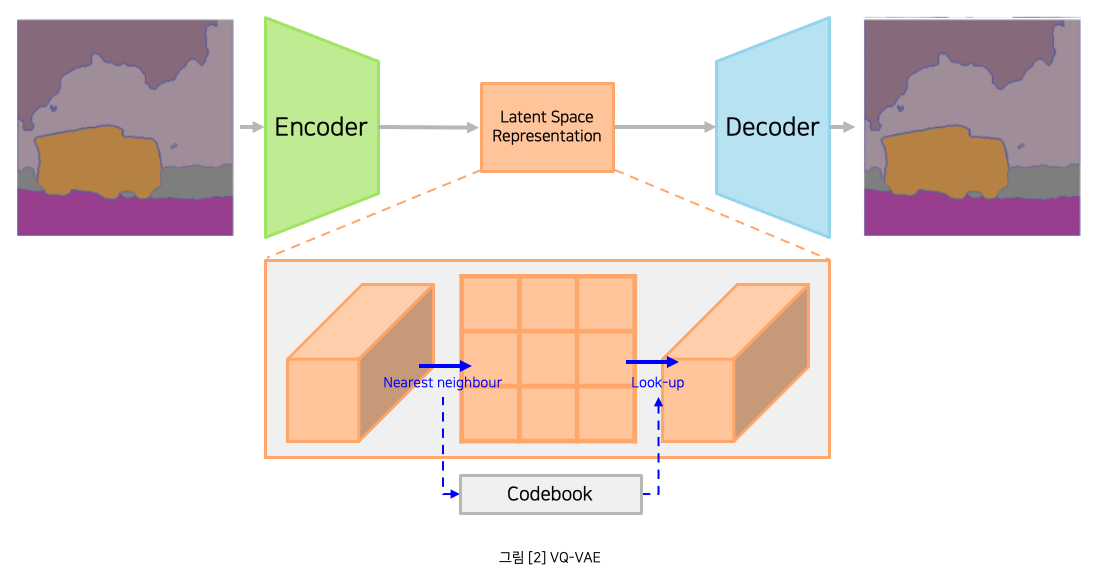
그런데 저희가 사용하는 CC3M과 같은 데이터셋은 이미지-텍스트 페어 데이터셋인데, 어떻게 학습에 사용할 세그멘테이션을 구하는 것일까요? 정답은 세그멘테이션 모델을 사용하여 이미지로부터 세그멘테이션을 추출하는 것입니다. Make-A-Scene에서는 아래와 같이 3개의 오픈소스 모델을 사용합니다.
| 세그멘테이션 | 모델 |
|---|---|
| Panoptic segmentation | Detectron2 |
| Human segmentation | Self-correction for human parsing |
| Face segmentation | How far are we from solving the 2d & 3d face alignment problem? |
위의 모델들을 사용하여 전처리하는 스크립트는 다음의 CasualGANPapers/Make-A-Scene[4]에서 확인하실 수 있습니다. 위 스크립트는 단일 프로세스에서 동작하도록 구현되어 있지만, 실제로는 많은 이미지를 전처리 해야 하기 때문에 ray 등의 멀티 프로세싱을 적용하여 시간을 단축해야 합니다.
이제 세그멘테이션 데이터를 얻었다면 세그멘테이션 토크나이저를 학습할 수 있습니다 ! 아래는 논문에서 언급한 간단한 전처리를 통해 얻은 세그멘테이션 데이터를 사용하여 토크나이저를 학습했을 때의 결과입니다.

위의 오른쪽 그림에서 보실 수 있는 것처럼, 아쉽게도 트레이닝을 시작한 지 얼마 지나지 않아 일부 클래스에 오버피팅이 되는 문제가 발생했습니다. 특히 보라색 영역으로 표시된 background 클래스에 주로 오버피팅이 되었는데, 이는 Human segmentation에서 사람의 신체 부위가 아닌 모든 위치가 background로 분류되었기 때문이라고 생각할 수 있습니다. 이와 같은 몇 가지 문제를 해결하기 위해 아래 3개의 전처리를 추가했습니다.
| 추가된 전처리 | |
|---|---|
| 1 | Human 세그멘테이션의 background 클래스 제거 |
| 2 | 각 픽셀이 하나의 세그멘테이션 라벨을 가지도록 수정 |
| 3 | Panoptic 세그멘테이션에 person 클래스가 없다면 Human, Face 세그멘테이션 제거 |
위와 같은 전처리를 적용했을 때 아래와 같이 의도대로 학습되는 것을 확인할 수 있습니다.

이미지 토크나이저
이미지 토크나이저 모델은 VQ-GAN을 사용하며 복원 성능을 끌어올리기 위한 몇 가지 loss를 추가하여 학습합니다. 하지만 mini Make-A-Scene에서는 학습 시간을 절약하기 위해 기존에 공개된 VQ-GAN 모델을 사용했습니다. 아래 그림에서 압축률(f)가 낮을수록 복원 성능이 우수한 것을 볼 수 있습니다. 하지만 압축률이 낮은 경우 GPT에서 예측해야 하는 토큰 수가 많아서 이미지 생성에 시간이 오래 걸린다는 단점이 있습니다. 또한 시퀀스 길이가 길어지면서 GPT 학습이 더욱 불안정해집니다.

위에서 언급했던 여러 요소를 고려하여 mini Make-A-Scene에서는 minDALL-E[5]의 VQ-GAN 모델을 사용했습니다.
트랜스포머 디코더
트랜스포머 디코더는 흔히 잘 알려진 GPT 모델을 사용합니다. GPT 모델은 입력 토큰을 사용하여 모든 출력 토큰에 대한 확률을 구하고, 소프트맥스 함수와 샘플링을 통해 출력 토큰을 결정합니다. 만약 정해진 수만큼 토큰을 출력하지 않았다면 다음 인퍼런스를 위해 선택된 출력 토큰을 다음 입력 토큰에 추가합니다. Make-A-Scene의 GPT 모델은 아래와 같이 DALL-E 모델에서 세그멘테이션 토큰 예측만이 추가된 형태입니다.
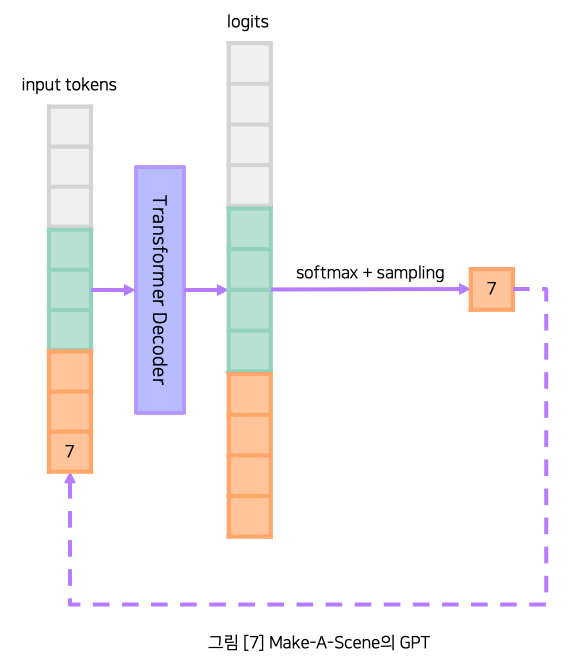
Make-A-Scene의 모델 크기는 4B으로 큰 편입니다. 이에 비해 mini Make-A-Scene의 모델 크기는 상대적으로 작은 270M으로, 약 14배 작은 파라미터를 사용하여 빠르게 학습했습니다.
| 모델 | 모델 크기 | 데이터셋 크기 |
|---|---|---|
| Make-A-Scene | 4B | 35M |
| mini Make-A-Scene | 270M | 14M |
학습한 GPT 모델에 세그멘테이션 데이터를 입력으로 제공하고 사용하여 생성한 이미지입니다. 텍스트는 "The elephant is walking around in the park"가 사용되었습니다.

결론
논문에 언급되지 않은 추가적인 전처리 방법을 적용하고 작은 크기의 모델과 데이터셋을 사용하여 mini Make-A-Scene을 학습해보았습니다. 비교적 적은 비용으로 Make-A-Scene을 학습하여 결과를 확인해볼 수 있었는데요. 하지만 텍스트 프롬프트에 따라 모델이 생성하는 세그멘테이션과 이미지의 품질이 낮은 경우가 있었습니다. 이를 위한 추가적인 성능 개선으로는 토크나이저 모델 변경, 토크나이저 압축률 변경, 모델 크기 증강, 데이터셋 증강 등 다양한 방법이 고려될 수 있습니다.
최근에는 Diffusion 모델이 여러 분야에서 좋은 성능을 내면서 많은 시도들이 이루어지고 있습니다. Diffusion 모델은 노이즈를 추가하는 정방향 프로세스와 노이즈를 제거하는 역방향 프로세스가 있으며, U-Net 모델을 통해 역방향 프로세스를 학습합니다. 또한 이미지 생성 분야 또한 성능이 우수하여 여러 연구들이 발표되고 있으며, GPT 기반 모델과 비교했을 때 비해 파라미터 수가 더 적고, 안정적으로 학습이 가능합니다. 모델을 여러 번 인퍼런스해야한다는 단점이 있지만 DDIM과 같이 시간 단축이 가능한 샘플러를 사용할 수 있다는 점에서도 GPT 기반 모델에 비해 좋다고 평가받고 있습니다.
따라서 저희는 멀티모달 모델의 성능을 높이기 위한 노력을 하고 있으며, GPT 기반 모델 외에도 Diffusion 모델을 사용하는 멀티모달 모델을 연구하고 있습니다.
참고 문헌
[1] Zero-Shot Text-to-Image Generation: https://arxiv.org/abs/2102.12092
[2] Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors: https://arxiv.org/abs/2203.13131
[3] Neural Discrete Representation Learning: https://arxiv.org/abs/1711.00937
[4] CasualGANPapers/Make-A-Scene: https://github.com/CasualGANPapers/Make-A-Scene
[5] kakaobrain/minDALL-E: https://github.com/kakaobrain/minDALL-E