

OpenAI가 지난해 공개한 대화형 모델 'ChatGPT[1]'는 최근 AI분야에서 가장 주목받고 있는 모델이라고 할 수 있습니다. 그 이유는 이 모델이 작문, 번역, 코딩 등 분야를 가리지 않고 사용자의 질문에 최적의 답변을 해줄 수 있기 때문입니다. 이번 게시글에서는 이 ChatGPT에 대해서 알아보고, 몇 가지 사용 예시를 보여드리도록 하겠습니다.
ChatGPT, 사람의 의도대로 답변을 생성하는 모델
ChatGPT는 GPT-3이라는 거대 인과적 언어 모델(Causal Language Model)에서 출발하였습니다. 인과적 언어 모델이란, 사용자의 입력을 보고 그 뒤에 나올 말들을 순차적으로 예측하는 모델을 말합니다. GPT-3은 아주 큰 트랜스포머 모델[2]을 방대한 양의 데이터에 학습시켜 모델이 문서 분류, 통역, 요약 등 다양한 분야에서 쓰일 수 있도록 하였습니다.
ChatGPT는 이 GPT-3에 담화 형태의 데이터를 가지고 특수한 방식으로 fine-tuning된 모델입니다. 기존의 GPT-3는 윤리적으로 부적절한 대답을 생성하거나, 질문자의 의도에 맞지 않는 대답을 생성하는 문제를 가지고 있었습니다. 이를 보완하기 위해 연구자들은 GPT-3에 사람의 '의도'를 학습시킬 수 있는 새로운 fine-tuning 방식을 개발하였습니다.
사람의 피드백을 이용한 강화 학습 (RLHF)

ChatGPT는 fine-tuning에 강화 학습을 사용합니다. ChatGPT의 답변이 얼마나 의도에 부합하는가 를 측정하는 reward 모델을 만들어 그 결과를 바탕으로 ChatGPT를 학습하는 방식입니다.
이때 모델의 학습을 위해 사람으로부터 두 가지의 피드백 데이터를 가져옵니다. 1) 질문의 의도에 맞는 답변 데이터, 2) 여러 답변들을 의도에 맞는 순서대로 나열한 데이터입니다. 첫 번째 데이터를 통해 ChatGPT를 일차로 fine-tuning하고, 두 번째 데이터를 통해 reward 모델을 학습한 후 마지막으로 학습된 reward 모델을 통해 ChatGPT를 다시 fine-tuning합니다.
ChatGPT의 사용 예시
OpenAI는 현재 사용자들이 무료로 ChatGPT를 사용해볼 수 있도록 데모 페이지[3]를 공개하고 있습니다. 데모 페이지에서 사용자들은 다양한 질문을 할 수 있고, 답변에 대한 평가를 내릴 수 있습니다.
작문은 ChatGPT가 가진 가장 강력한 능력 중 하나입니다. 인과적 언어 모델의 특성상, 생성에 우수한 면모를 보이기 때문입니다. 몇 가지 키워드를 주면 하나의 이야기를 써내려갈 수도 있고, 주제를 주면 그럴듯한 에세이를 작성하기도 합니다.

ChatGPT의 학습 데이터에 다양한 언어가 포함되어있기 때문에 각국의 언어를 다른 언어로 번역하는 작업을 할 수도 있습니다. 특정 단어가 어떻게 번역되었는지 보여주는 역할도 같이 수행합니다.

또한 단순 번역이 아니라 아예 담화 자체를 한국어로 진행할 수도 있습니다.

눈여겨볼 점은 ChatGPT가 이전의 담화를 참고하여 적절한 답변을 찾아낸다는 것입니다. 이를 통해서 답변에 대한 변경 요청이나 추가적인 질문 역시 가능합니다.


그러나 ChatGPT도 만능은 아닙니다. 공식 블로그[1]에 따르면 위 모델은 2021 이전의 데이터로만 학습되었기 때문에, 그 이후의 데이터를 필요로 하는 질문에는 답을 할 수 없다는 문제점을 가지고 있습니다. 또한 겉보기에는 그럴듯하지만 사실은 틀린 답을 내놓을 수도 있습니다.
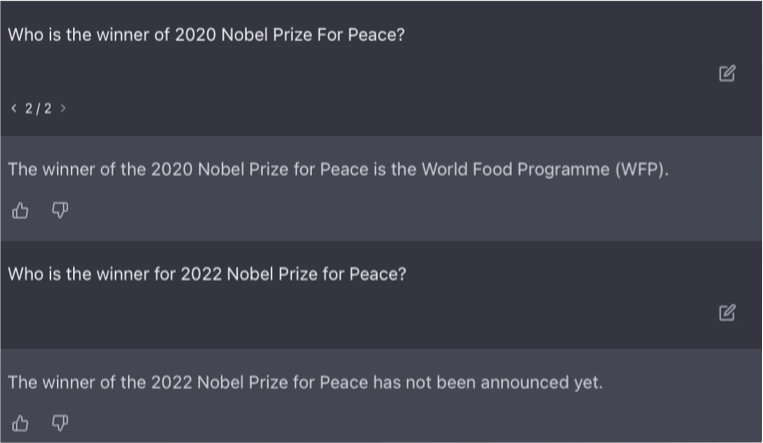

이러한 문제점이 존재하기는 하지만, ChatGPT는 여전히 광범위한 주제에 대한 지식 제공이라는 큰 메리트를 가지고 있습니다. 따라서 ChatGPT는 판단/결정이나 작업을 지원하는 도구로서 아주 뛰어나다고 볼 수 있습니다.
참고 문헌
[1] https://openai.com/blog/chatgpt/
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[3] https://chat.openai.com/